Our team is using custom formulas in MS Project to generate the low/high estimates and statistical distribution of durations based upon the syntax that is documented in your user documentation. Using this, we have develop specific risk profiles for types of activities that allows us to quick generate the data required to run a simulation using your MSP Addin.
We are concerned in regard to the generation of the Seed values. How does this impact the results of the simulation?
Generating seed numbers using formula fields
Moderator: Intaver Support
-
Intaver Support
- Posts: 1031
- Joined: Wed Nov 09, 2005 9:55 am
Re: Generating seed numbers using formula fields
Seed values are fundamental to generating the random numbers that are required for the Monte Carlo simulation. They are generated randomly by our system, but once set, the values that are sampled from the statistical distributions during each iteration are deterministic. So, If two task have the same seed value then they will be 100% correlated in terms of what value of the PDF (Probability Distribution Function) is selected for each iteration. So what this means is if they are correlated, the same probability value sampled from each activity will be selected on each iteration. I
In practical terms correlated activities is appropriate if you believe that they are going to be affected by the same issues. For example, if production rate is low, all effected tasks will take longer and by the same relative amount.
In this example, using our MSP Addin, the tasks low and high estimates are calculated based on the coefficients, but the correlation option is not selected.
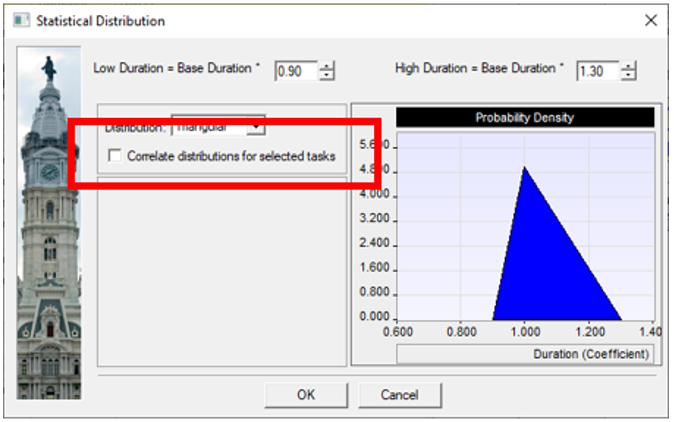
This generates the following data in MSP. If we look in the code generated for the simulation, the assigned seed values are different.

If we duplicate this, but use the correlation option, the seed values are identical. This means that each of these tasks will relative durations for each iteration and will simulate they are being impacted by the same factor.

It is similar phenomena when we create risks assignments. By default, risk assignments are correlated, in this way if a risk occurs during an iteration, it impacts all of the tasks to which the risk is assigned. When risks are correlated, the risk assignments for each task have the same seed.
Rather than using task correlations, we recommend using risk assignments to model correlations either as a risk: <100% probability, or an issue: 100% probability.
In practical terms correlated activities is appropriate if you believe that they are going to be affected by the same issues. For example, if production rate is low, all effected tasks will take longer and by the same relative amount.
In this example, using our MSP Addin, the tasks low and high estimates are calculated based on the coefficients, but the correlation option is not selected.
This generates the following data in MSP. If we look in the code generated for the simulation, the assigned seed values are different.
If we duplicate this, but use the correlation option, the seed values are identical. This means that each of these tasks will relative durations for each iteration and will simulate they are being impacted by the same factor.
It is similar phenomena when we create risks assignments. By default, risk assignments are correlated, in this way if a risk occurs during an iteration, it impacts all of the tasks to which the risk is assigned. When risks are correlated, the risk assignments for each task have the same seed.
Rather than using task correlations, we recommend using risk assignments to model correlations either as a risk: <100% probability, or an issue: 100% probability.
Intaver Support Team
Intaver Institute Inc.
Home of Project Risk Management and Project Risk Analysis software RiskyProject
www.intaver.com
Intaver Institute Inc.
Home of Project Risk Management and Project Risk Analysis software RiskyProject
www.intaver.com